
FlashAttention — это оптимизированный алгоритм вычисления attention в трансформерах. Он быстрее, экономичнее по памяти и лучше масштабируется, чем стандартный attention. Впервые представлен в статье FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness и с тех пор стал стандартом для обучения и инференса современных LLM.
Почему attention работает медленно#
Когда LLM читает текст, она должна сравнить каждый токен с каждым другим, чтобы понять взаимосвязи. Это и есть attention.
У стандартного attention есть фундаментальная проблема: он упирается в память, а не в вычисления. Чтобы понять это, посмотрим, что происходит при вычислении attention.
Стандартный attention вычисляется так:
$$ \text{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$Наивная реализация делает следующее:
- Вычисляет attention-оценки: перемножает Q и K^T, получая матрицу N×N (N — длина последовательности)
- Применяет softmax: нормализует оценки
- Умножает на значения: считает взвешенную сумму с V
Проблема — в паттерне доступа к памяти. Современные GPU имеют:
- HBM (High Bandwidth Memory): большая, но медленная (1–2 ТБ/с)
- SRAM (on-chip memory): маленькая, но быстрая (10–20 ТБ/с)
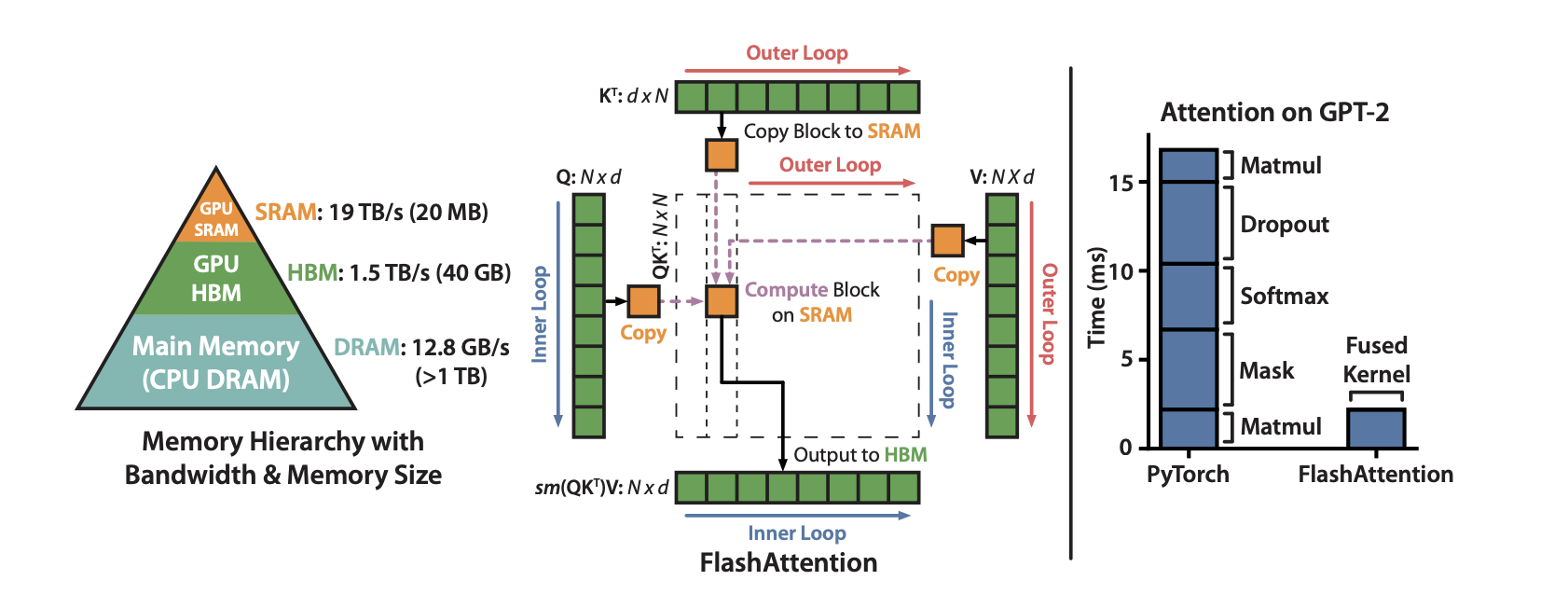
Стандартная реализация требует записывать всю матрицу attention N×N в HBM, а затем читать её обратно для следующей операции. Для последовательности длиной 4096 токенов эта матрица содержит ~16 млн элементов. Из-за многократных чтений/записей большая часть времени уходит на передачу данных, а не на вычисления.
С ростом длины последовательности:
- Трафик памяти доминирует во времени работы
- Загрузка GPU падает
- Длинные контексты становятся непрактичными
Например, 16K токенов требуют в 256 раз больше памяти, чем 1K токенов.
Как работает FlashAttention#
FlashAttention ускоряет attention за счёт снижения трафика памяти. Ключевая идея — никогда не хранить всю матрицу attention в HBM. Вместо этого используются два приёма:
- Тайлинг и пересчёт. FlashAttention разбивает вычисления на блоки (тайлы), которые помещаются в быструю SRAM:
- Загружает тайлы Q, K, V из HBM в SRAM
- Считает attention для тайла полностью в SRAM
- Инкрементально обновляет выход и сразу отбрасывает промежуточные результаты
- Фьюзинг ядер. Вместо отдельных операций (matmul → softmax → matmul) всё объединено в одно GPU-ядро:
- Нет записи промежуточных результатов в HBM
- Нет отдельных запусков ядер (меньше overhead)
- Всё происходит в быстрой SRAM
Проще говоря, FlashAttention делает вычисления attention эффективнее: GPU меньше ждёт память и больше считает.
Преимущества FlashAttention#
FlashAttention даёт серьёзный прирост скорости и масштабируемости:
- Attention в 2–4 раза быстрее
- Гораздо меньше памяти, так как матрица N×N не хранится
- LLM могут работать с длинными контекстами (например, 128K токенов)
- Выше throughput и загрузка GPU
- Быстрее инференс для чата, кода, reasoning и др.
Сегодня FlashAttention широко используется в:
- Фреймворках обучения (PyTorch, DeepSpeed)
- Движках инференса (vLLM, SGLang, Hugging Face TGI, TensorRT-LLM)
- Архитектурах моделей с длинным контекстом
- Inference engines (vLLM, SGLang, Hugging Face TGI, TensorRT-LLM)
- Model architectures that support long context
Сравнение версий FlashAttention#
На сегодня у FlashAttention 4 основных версии. Вот сравнительная таблица, как алгоритм развивался:
| Версия | Год | Ключевые улучшения | Производительность | Примечания |
|---|---|---|---|---|
| FlashAttention-1 | 2022 | IO-aware тайлинг, фьюзинг softmax+matmul, не хранит всю матрицу attention | Attention в 2–4 раза быстрее, до 10× меньше памяти | Первая версия; поддержка длинных контекстов; точный attention (без аппроксимаций) |
| FlashAttention-2 | 2023 | Лучшая параллелизация и разбиение работы по warp; меньше FLOPs вне matmul | В 2 раза быстрее FA-1, особенно на длинных последовательностях | Используется во многих LLM с длинным контекстом; интегрирован в фреймворки |
| FlashAttention-3 | 2024 | Ускорение на tensor core (FP8/BF16); оптимизация под Hopper (H100) | До 2× быстрее FA-2, 740 TFLOPS на H100 (75% загрузки); FP8-ошибки снижены в 2.6× | Новейшая версия; использует новые возможности GPU. Многие фреймворки ещё на FA-2 |
FlashAttention 4 официально не вышел, но Tri Dao показал превью на HotChips: он до 22% быстрее attention-ядра из cuDNN.
Как использовать FlashAttention#
Самый простой способ начать — установить официальный пакет:
pip install flash-attn --no-build-isolationВ новых версиях PyTorch поддержка FlashAttention включается автоматически через scaled_dot_product_attention, если возможно. Подробнее — в API reference.
Многие inference-фреймворки уже интегрировали FlashAttention, например vLLM и SGLang, но версии могут отличаться в зависимости от релизного цикла.